Photo credit Georgetown University.
Querying, Analyzing and Downloading
The entire GDELT database is 100% free and open and you can
download the raw datafiles, visualize it using the
GDELT Analysis Service, or analyze it at limitless scale with Google BigQuery.
The GDELT Project is the largest, most comprehensive, and highest resolution open database of human society ever created. Just the 2015 data alone records nearly three quarters of a trillion emotional snapshots and more than 1.5 billion location references, while its total archives span more than 215 years, making it one of the largest open-access spatio-temporal datasets in existance and pushing the boundaries of "big data" study of global human society. Its Global Knowledge Graph connects the world's people, organizations, locations, themes, counts, images and emotions into a single holistic network over the entire planet. How can you query, explore, model, visualize, interact, and even forecast this vast archive of human society?
Free cloud-based service that offers a variety of tools and services to allow you to visualize, explore, and export GDELT - a great way to get started using GDELT for the first time.
Query, export, and even conduct sophisticated analyses and modeling of the entire dataset using standard SQL, with even the most complex queries returning in near-realtime.
Advanced users and those with unique use cases can download the entire underlying event and graph datasets in CSV format - over 2.5TB for last year alone.
All of GDELT's documentation in one place - user manuals, codebooks, lookup files, and normalization spreadsheets are all found here.
Visualization credit GDELT Project.
GDELT Analysis Service
Visualize, analyze, explore, and export GDELT right from your browser.
The GDELT Analysis Service is a free cloud-based service that offers a variety of tools and services to allow you to visualize, explore, and export both the GDELT Event Database and the GDELT Global Knowledge Graph. This is a great way to get started exploring GDELT and what it can do for you, even if you don't have a technical background.
NOTE: The Analysis Service currently searches only GDELT 1.0, an upgrade is planned for later this year to integrate all of the GDELT 2.0 datasets.
Visualization & Format Translation
Fourteen different tools are available for geographic, temporal, network, and contextual visualizations of both the Event Database and Global Knowledge Graph. No technical expertise is required - you just select the visualization you want, enter your query, and a few minutes later it is delivered right to your email inbox!
A common thread we've heard from all of you is the need for a central set of tools that make it easier to work with GDELT and that can translate its rich multidimensional knowledgebase into file formats and visualizations that analysts and scholars can better make sense of and that are compatible with the toolkits and software you use each day. To this end, each of the tools offers the ability to output in a wide array of relevant file formats, from CSV to Google Earth to Gephi, allowing you for example to construct a network of influencers around an industry and output it as a Gephi file for further analysis.
Data Export
Often the GDELT Analysis Service is the best place to start when testing out a hypothesis or checking for an emergent trend. You can instantly test out a new query, getting results back in just a few moments, iteratively adjusting your search to see if there is anything worth exploring further. When you find something of interest that you want to explore, visualize, or analyze in more detail, the Analysis Service has a wide range of export options, from speciality file formats to raw export of the underlying CSV records.
If you are trying to locate all attacks on civilians in a certain country over a four-month period, use the TimeMapper tool to determine if there are enough matching events or if you need to adjust your query further, and then use the Exporter tool to download a CSV file containing just the matching records.
Photo credit Google.
Google BigQuery
Leverage the world's most powerful database platform for realtime querying and analysis.
Given their massive size and complexity, most users will struggle to make full use of GDELT's datasets on their local computers. Just the 2015 GKG dataset alone weighs in at over 2.5TB and contains more than three quarters of a trillion emotional scores. To make analyses at such scales possible, all GDELT datasets are available in Google BigQuery, with live datasets updated every 15 minutes. You can query, export, and even conduct sophisticated analyses and modeling of the entire dataset using standard SQL, with even the most complex queries returning in near-realtime. See the full list of tables available in BigQuery.
GDELT + BigQuery = Query The Planet
From the very beginning, one of the greatest challenges in working with GDELT has been in how to interact with a dataset of this magnitude. Few database platforms can handle a dataset this complex with the sheer variety of access patterns and the number of permutations of fields that are collected together into queries each day.
Google's BigQuery database was custom-designed for datasets like GDELT, enabling near-realtime adhoc querying over the entire dataset. This means that no matter how you access GDELT, what columns you look across, what kinds of operators you use, or the complexity of your query, you will still see results pretty much in near-realtime.
Realtime Analysis
For us, the most groundbreaking part of having GDELT in BigQuery is that it opens the door not only to fast complex querying and extracting of data, but also allows for the first time real-world analyses to be run entirely in the database.
Imagine computing the most significant conflict interaction in the world by month over the past 35 years, or performing cross-tabbed correlation over different classes of relationships between a set of countries. Such queries can be run entirely inside of BigQuery and return in just a handful of seconds. This enables you to try out "what if" hypotheses on global-scale trends in near-real time.
Visualization credit GDELT Project.
Raw Data Files
Download all of GDELT to your own computer.
Advanced users and those with unique use cases can download the entire underlying event and graph datasets in CSV format. Deep technical knowledge and extensive experience working with large datasets is required to make use of these datasets, with the 2015 GKG alone requiring more than 2.5TB.
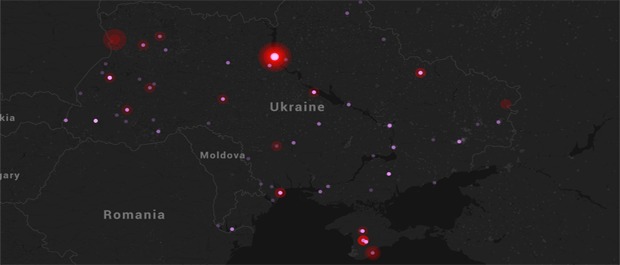
GDELT 1.0 Event Database
The GDELT 1.0 Event Database contains over a quarter-billion records organized into a set of tab-delimited files by date. Through March 31, 2013 records are stored in monthly and yearly files by the date the event took place. Beginning with April 1, 2013, files are created daily and records are stored by the date the event was found in the world's news media rather than the date it occurred (97%+ of events are reported within 24 hours of happening, but a small number of events each day are past events being mentioned for the first time - if an event has been seen before it will not be included again). Files are ZIP compressed in tab delimited format, but named with a ".CSV" extension to address some software packages that will not accept .TXT or .TSV files.
Each morning, seven days a week, the latest daily update is posted by 6AM EST. This file is named with the previous day's date in the format "YYYYMMDD.export.CSV.zip" (ie the morning of May 24, 2013 a new file called "20130523.export.CSV.zip" is added). UNIX or Linux users can easily set up a cronjob or other automatic scheduling processes to automatically download the latest daily update each morning and process it for watchboarding, forecasting, early warning, alert services, and other applications.
There is also a special GDELT 1.0 "reduced" event dataset (1.1GB) that uses the "one a day" country-level filtering commonly used in older academic event databases. This version of the data will most closely match the aggregation level users with previous event analysis experience are familiar with and collapses the database on "DATE+ACTOR1+ACTOR2+EVENTCODE" (ie every protest held anywhere in Russia on a given day is collapsed to a single entry). This version is recommended only for those needing compatibility with analyses based on previous generations of academic event databases and covers the period January 1, 1979 to February 17, 2014. It is not updated.

GDELT 1.0 Global Knowledge Graph (GKG)
The GDELT 1.0 Global Knowledge Graph begins April 1, 2013 and consists of two parallel data streams, one encoding the entire knowledge graph with all of its fields, and the other encoding only the subset of the graph that records "counts" of a set of predefined categories like number of protesters, number killed, or number displaced or sickened. Such counts may occur independently of the CAMEO events in the primary GDELT event stream, such as mentions of those killed in industrial accidents (which are not captured in CAMEO) or those displaced by a natural disaster or sickened by a disease epidemic. In this way, the GKG Counts File can be used to produce a daily "Death Tracker" to map all mentions of death across the world each day, or an "Affected Tracker" to indicate how many persons were sickened/displaced/stranded each day (at least as recorded in the global news media). These files are named as "YYYYMMDD.gkg.csv.zip" and posted by 6AM EST each morning seven days a week.
The second file is the full graph file, which contains the actual graph connecting all persons, organizations, locations, emotions, themes, counts, events, and sources together each day. It also contains a list of the EventIDs of each event found in the same article as the extracted information, allowing rich contextualization of events. These files are named as "YYYYMMDD.gkgcounts.csv.zip" and posted by 6AM EST each morning seven days a week.
The Global Knowledge Graph is currently in "alpha" release and may change over time as we introduce new capabilities and expand its underlying algorithms.
GDELT 2.0 Event Database
GDELT 2.0 adds a wealth of new features to the event database and includes events reported in articles published in the 65 live translated languages. The core event table is largely the same with a few additional columns, but there is a new "mentions" table and several other changes and the data updates every 15 minutes.
GDELT 2.0 Global Knowledge Graph (GKG)
GDELT 2.0's Global Knowledge Graph (GKG) adds a vast wealth of new features, incorporates the 65 live translated languages and updates every 15 minutes.

GDELT Visual Global Knowledge Graph
The GDELT Visual Knowledge Graph applies Google's most powerful deep learning algorithms to global news imagery in order to catalog the visual narratives of the world's media in realtime.
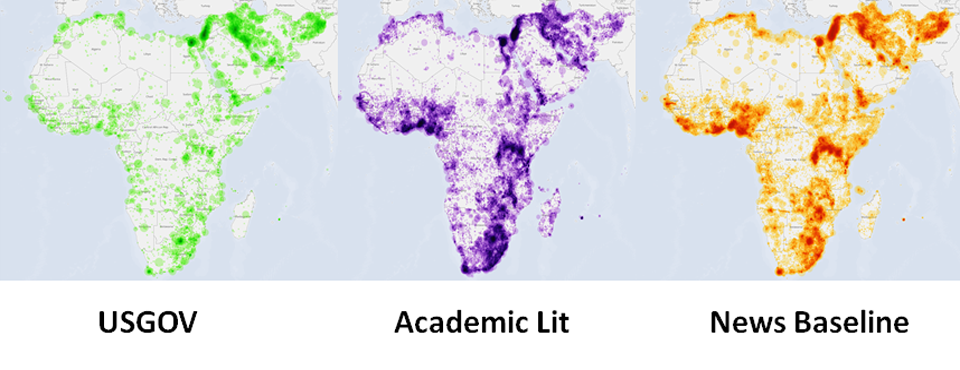
GDELT GKG Special Collections
In addition to the news-based Global Knowledge Graph (GKG) updated every 15 minutes and based on global news reporting, there are numerous special GKG collections available that focus on specific specialized sources of information or topics, from 21 billion words of academic literature to 215 years of books.

GDELT Global Frontpage Graph
The GDELT Frontpage Graph scans the homepages of 50,000 major news outlets across the world every hour and compiles a master inventory of their homepage links, cataloging the editorial decisions of the world's news landscape and what each outlet considers the most "important" stories of the moment.

GDELT Summary + GDELT APIs
In addition to its datasets, GDELT also offers a number of live realtime JSON APIs offering fulltext search and other capabilities, including DOC, GEO and TV. Explore them using GDELT Summary that offers a non-technical human friendly website wrapper around the APIs, showcasing their capabilities.

GDELT Global Difference Graph
The GDELT Global Difference Graph rescans every news article after 24 hours and after one week and compares them against the original version to catalog all changes that have been made, from 404's and redirects to stealth editing, offering for the first time a global look at how our news is being silently rewritten hour by hour.

GDELT Television Ngrams
Unigram and bigram ngram datasets are available for a dozen stations back a decade at 30 minute resolution and updated daily.

GDELT Visual Global Entity Graph
The GDELT Visual Global Entity Graph non-consumptively annotates American television news programming of the past decade through Google's Cloud Video AI API in collaboration with the Internet Archive's Television News Archive.

GDELT Global Entity Graph
Entity identifications from more than 100 million news articles annotated through Google's Cloud Natural Language API.

GDELT's Open AI Datasets
A compilation of some of GDELT's main AI annotation datasets, including video, vision, speech and text.
Media-Data Research Consortium Covid-19 Datasets
The Media-Data Research Consortium (M-DRC), whom GDELT has been working closely with to analyze television news, was awarded a Google Cloud COVID-19 Research Grant to support "Quantifying the COVID-19 Public Health Media Narrative Through TV & Radio News Analysis." You can download all of the resulting datasets.
GDELT Web Ngrams
Global online news ngrams in 152 languages.
GDELT TV News Advertising Inventory Datasets
A collection of annotated datasets that precisely inventory advertising across television news, including closed captioning TTXT files of captioned ads and both caption-time and video-time masking files.

GDELT Global Embedded Metadata Graph
The Global Embedded Metadata Graph (GEMG) records the hidden semantic metadata in news articles that underlie the modern web, spanning July 2018 to present. From Open Graph objects in HTML tags to rich Schema.org annotations expressed in JSON-LD blocks, the GEMG is designed to capture the rich descriptive structured metadata that is provided with many news articles.

GDELT Global Quotation Graph
The GDELT Global Quotation Graph records quoted statements across worldwide online news in 152 languages, offering rich insights into public statements.

GDELT Global Relationship Graph
The Global Relationship Graph is an experimental new initiative in codifying the factual claims and relationships made in the global press each day that is currently instantiated as realtime verb-centered ngrams.

GDELT Global Geographic Graph
The GDELT Global Geographic Graph is the underlying dataset powering the GDELT GEO 2.0 API, covering more than 1.6 billion location mentions from worldwide English language online news coverage back to April 4, 2017, with full details of each mention, including a 600-character contextual snippet of its context and usage.
Visualization credit GDELT Project.
Documentation
All there is to know about using GDELT.
You'll find all of GDELT's documentation in this section, from user manuals to codebooks, lookup files to normalization spreadsheets.
GDELT 1.0 Event Database
The following documentation describes the GDELT 1.0 Event Database, its major data fields and their descriptions and formats, and the codebook for the CAMEO event taxonomy. Remember that GDELT 1.0 only updates daily and does NOT include events reported in the 65 live translated languages.
GDELT 2.0 Event Database
GDELT 2.0 adds a wealth of new features to the event database and includes events reported in articles published in the 65 live translated languages. The core event table is largely the same with a few additional columns, but there is a new "mentions" table and several other changes and the data updates every 15 minutes.
GDELT 1.0 GKG
The following documentation describes the GDELT 1.0 Global Knowledge Graph (GKG), its major data fields and their descriptions and formats. Remember that GDELT 1.0 only updates daily and does NOT include coverage from the 65 live translated languages.
GDELT 2.0 GKG
GDELT 2.0's Global Knowledge Graph (GKG) adds a vast wealth of new features, incorporates the 65 live translated languages and updates every 15 minutes.
GDELT Visual GKG 1.0
The GDELT Visual Knowledge Graph applies Google's most powerful deep learning algorithms to global news imagery in order to catalog the visual narratives of the world's media in realtime.
GDELT 2.0 GKG Special Collections
In addition to the news-based Global Knowledge Graph (GKG) updated every 15 minutes and based on global news reporting, there are numerous special GKG collections available that focus on specific specialized sources of information or topics, from 21 billion words of academic literature to 215 years of books.
EVENT CAMEO Actor Code Lookups
The GDELT 1.0 and 2.0 Event Databases use the CAMEO event taxonomy, which records the actors involved in an event as a series of 3-character codes. These tab-delimited lookup files contain the human-friendly textual labels for each of those codes to make it easier to work with the data for those who have not previously worked with CAMEO. Remember that CAMEO Country Codes are only used in the "Actor" fields, while FIPS Country Codes are used in the "Geo" fields.
EVENT CAMEO Event Code Lookups
The GDELT 1.0 and 2.0 Event Databases use the CAMEO event taxonomy, which is a collection of more than 300 types of events organized into a hierarchical taxonomy and recorded in the files as a numeric code. These tab-delimited lookup files contain the human-friendly textual labels for each of those codes to make it easier to work with the data for those who have not previously worked with CAMEO.
GDELT 1.0 Event Database Normalization Files
The comma-delimited (CSV) files below are updated daily and record the total number of events in the GDELT 1.0 Event Database across all event types broken down by time and country. This is important for normalization tasks, to compensate the exponential increase in the availability of global news material over time. Due to GDELT 2.0's live updating, we do not currently make normalization files available for GDELT 2.0, but you can easily construct your own normalization files by performing a basic summation over the 15 minute update files.
Getting Started with GDELT
GDELT is the largest, highest resolution, and most detailed open dataset of global human society ever created. This means that working with it can require a lot of careful attention to things like normalization that are often unfamiliar to many disciplines. Later this year we will be releasing a "Getting Started With GDELT" guide to walk you through how to work with the breathtakingly massive look at global society that is GDELT. For now, keep a close eye on the GDELT Blog, where we post regular tutorials, examples and updates.